This post will cover two recent additions to my local Shadertoy development platform, or "DemoRun" as it's named.
In Shadertoy you can run four additional shaders that renders to their own texture ("Buffer" A, B, C, D) which can be read by the others. This allows for effects that require multiple passes as well as simulations since we can read from the the previous frame.
I knew I would require this feature sooner or later and below follows a few notes on how I went about to implement it.
A DemoRun session is invoked like this.
./DemoRun *Path to shader source file*
Only one argument, the path to the source. Nice and simple and I wanted to keep it that way, but now we can have multiple shaders, each with their own source file so now we need some way of telling which is which and their inputs.
I went with specifying everything in the sources, using C preprocessor syntax. Here's the currently available parameters.
#source bufferA "FirstPass.cpp" #source bufferB "SecondPass.cpp" #input bufferB #range gb -1 1 #range r -2 0 #clear 0.25 0.5 0.75
#source Only applicable to the main entry file. It tells which buffer to enable and the path to its source.#input As the name suggests, assigns a buffer as input. The same name will be used when accessing the texture.#range The range that will be mapped to 0-1 when the buffer is rendered for display. First argument specify the color channels. Unspecified channels will be assigned default values.#clear The RGB value to clear the framebuffer to before rendering the display buffer. Used for easier inspection of the alpha channel.v4 samp = Sample(bufferA, texCoord);
On a side note, I use the .cpp extension primarily to get the most out of 4Coder features, but also since I use my own flavor of glsl that supports include directives. The source code will get parsed and converted into legal glsl and so I want to distinguish between the different formats.
All settings directives must come before anything else in the source file. This makes things easier as we can then just offset the first row to read from when parsing the actual code.
In regards to parsing, I took the opportunity to implement another much needed feature.
Previously I had file inclusion performed in conjunction with code parsing, which is a waste of work if later some file can't be opened, besides making the routine more complicated.
The greater problem though was that, when compiling, any error messages would point to locations in the generated source, not the original. In order to point to the original we need to somehow map between the two.
To achieve this I first split the routine into two steps. The first one handles all the file inclusion and lexing. This is a recursive process that builds an array of "blocks" that contain the mapping information we need.
struct LexBlock { String name; Lexer* lex; u32Range locRows; };
Sources are now self contained in memory with their own lexer. name refers to the file name, locRows tells the local range of rows that make up the block.
A source file is initally mapped to one block. Upon encountering an #include directive the current block is split and the new blocks are added subsequentially, then followed by the remaining part of the "parent" block.
The resulting blocks will be used as input for the second step, parsing and code generation. The generated source is laid out according to the blocks.
To complete the mapping we need to know the corresponding rows for each block in the combined source. Since the rows map one to one in this case, calculating the absolute ranges is just a matter of adding up the local ones.
u32 offset = 0; for (/*each block*/) { u32 numRows = block->locRows.end - block->locRows.begin; block->absRows.begin = offset; block->absRows.end = offset + numRows; offset = block->absRows.end; }
You may have noticed that LexBlock does not store an absolute range. Things got complicated since the generated source is only one part of the actual compiled source, which includes pregenerated strings containing all the necessary shader setup as well as the buffer input declarations.
For the final mapping a new block array is built using this struct instead.
struct TextBlock { String name; u32Range locRows; u32Range absRows; };
The strings each get their own block, and the lexer blocks are transferred. Now we can calculate the absolute ranges which completes the mapping and move on to compilation!
The error log received from OpenGL will be parsed and a new string will be generated containing the error messages and file locations.
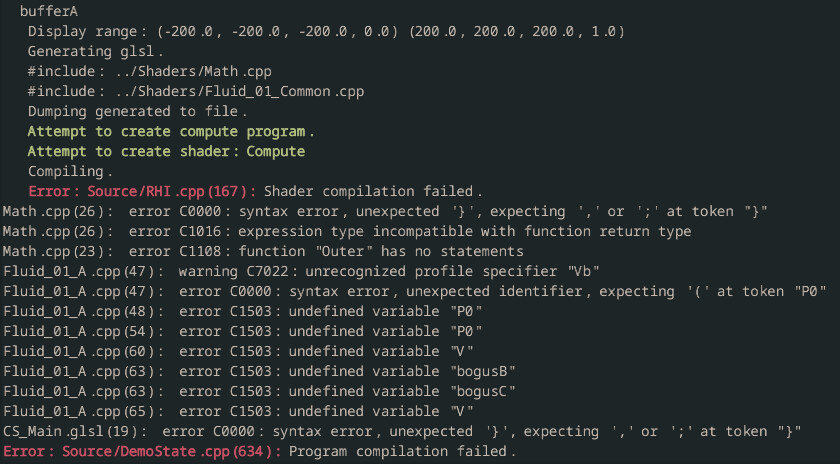
Shadertoy gives access to an additional text buffer called "Common" whose contents will be shared between all shaders. Since my system already implements arbitrary includes there is no point in supporting this feature internally.
Since "Main" ("Image" in Shadertoy) is the entry point it's settings are parsed first, which requires it to be lexed, then follows a procedure to open and lex any additional buffer sources.
The buffers and Main are then listed together, allowing them to go through the same pipeline without exception. Every major step is performed on all entries before moving on to the next, in order to catch errors sooner as well as just keeping everything more manageable.
All output textures are being rendered with compute shaders. Whichever texture is set to be displayed is drawn as a full-screen quad. It's likely that the buffer textures will contain values outside the 0-1 range so the sampled color will be mapped from the value provided in #range.
All textures are stored as RGBA floating point.

In Shadertoy a buffer shader can use its own output as input. I went for the typical double buffered scheme and looking around at the code it would appear that Shadertoy does the same.
Nothing special in terms of implementation but an important addition none the less.
During each frame, the shaders are clocked on the CPU. Since GPU commands are buffered and executed later, in order to get valid timings we need to tell OpenGL to execute all currently queued up commands immediately and stall the CPU-client until finished.
I suspect that this is by far not the most accurate approach but it certainly serves my case well enough.
// Dispatch routine for each shader. s64 begin_us; if (profile) { begin_us = Clock_us(); } RHI_DispatchCompute(prog, numGroups); if (profile) { // Wait for shader dispatch to finish. RHI_Finish(); // Update frame timings specific to this buffer. s64 end_us = Clock_us(); f32 ms = (f32)(end_us - begin_us) * 0.001f; u32 i = prog - State.bufProg; u32 head = Profile.head; Profile.frames[i][head] = ms; Profile.tMin[i] = Min(Profile.tMin[i], ms); Profile.tMax[i] = Max(Profile.tMax[i], ms); // Accumulate total time for this frame. tFrame += ms; }
RHI_Finish() just calls glFinish() which does as described above.
Here's the code for the clock function, which returns the current time in micro seconds.
#include <time.h> s64 Clock_us() { timespec t; clock_gettime(CLOCK_MONOTONIC, &t); return (t.tv_sec * 1000000) + (t.tv_nsec / 1000); }
The profiler state.
#define PROF_FRAMES_NUM 128 struct { s32 head = 0; u32 active = 0; f32 tMin [6] = {1000.0f, 1000.0f, 1000.0f, 1000.0f, 1000.0f, 1000.0f}; f32 tMax [6] = {0.0f}; f32 frames[6][PROF_FRAMES_NUM] = {0}; } Profile;
frames store the frame timings in circular buffers, one for each shader and the frame total. This information is then used directly to draw all the gui stuff, which include time graphs and statistics.

Til next time, thank you for reading!